
728x90
올바른 결과를 도출하기 위해서는 데이터 전처리 과정을 거쳐야한다. 넘파이로 데이터를 준비하고 사이킷런으로 훈련 세트와 테스트 세트를 나누어주었다. 데이터 전처리 전에 나오는 결과에서 오류를 찾고, k-최근접 이웃을 이용하여 산점도를 다시 그려보고 기준을 수정하였다.


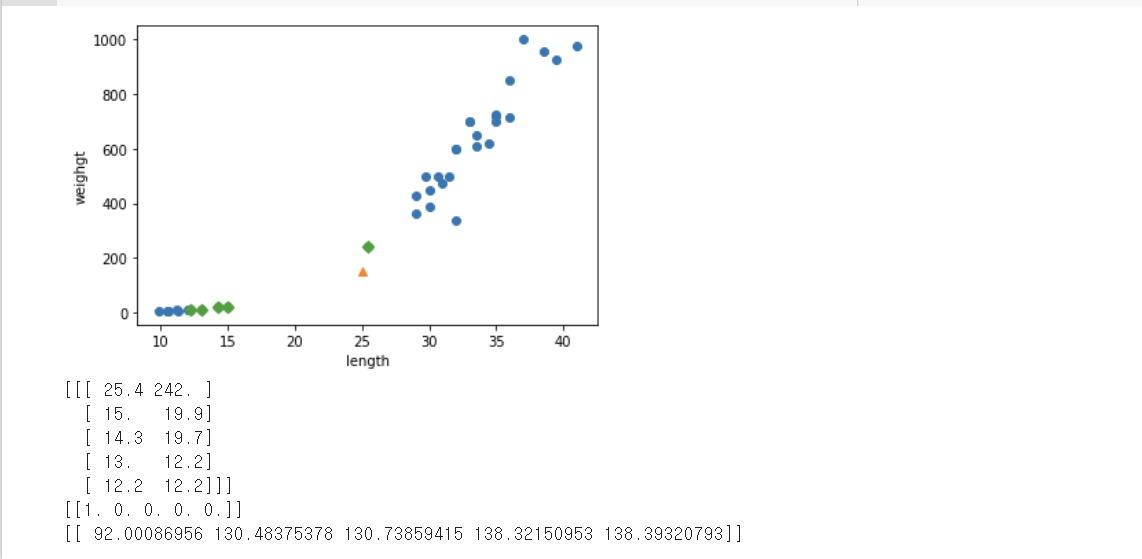

왼쪽은 데이터 전처리 작업을 하기 전, 오른쪽은 전처리 작업을 한 후로 나타난 결과이다. 다음은 표준점수를 통해 전처리를 하는 방법이다. 훈련 세트를 mean으로 빼고 std로 나누어 주었기 때문에 값의 범위가 달라져 샘플 하나가 혼자 덩그러니 놓여져있는 상태이다. 코드를 수정한 후, 결과를 보면 산점도와 거의 동일하다. 하지만 x축과 y축의 값이 크게 변한 것을 볼 수 있다.


테스트세트도 훈련 세트의 평균과 표준편차로 변환해야한다. 테스트 세트의 스케일을 변환하고 정확도를 측정해보면 1.0으로 100%가 나온다. 그리고 다시한번 샘플 데이터를 예측해보면 드디어 도미로 나오는 것을 볼 수 있는 실습이었다. 사실 특성의 스케일을 조정하는 방법은 표준 점수 말고도 더있지만, 대부분의 경우 이 방법으로 충분하다고 한다.


출처 : 혼자 공부하는 머신러닝 + 딥러닝_박해선 지음
728x90
'AI > Machine Learning&Deep Learning' 카테고리의 다른 글
| MachineLearning_분류(Classification) (0) | 2021.03.22 |
|---|---|
| Machine Learning_일차함수 관계식 찾기 (0) | 2021.03.20 |
| Machine Learning_훈련 세트와 테스트 세트 (0) | 2021.03.19 |
| Machine Learning_k-최근접 이웃 알고리즘 (0) | 2021.03.15 |
| Machine Learning_지도학습 vs. 비지도학습 (0) | 2021.01.29 |