
728x90
로지스틱 회귀(Logistic Regression)는 회귀라는 이름으로 되어있지만 실제로 분류알고리즘에 속한다.
시그모이드 함수의 출력값(0~1)을 각 분류 클래스에 속하게 될 확률 값으로 사용한다. 확률이 1에 가까우면
해당클래스로 분류하고, 0에 가까우면 아니라고 분류한다.
LogisticRegression은 기보넞ㄱ으로 릿지 회귀와 같이 계수의 제곱을 규제한다. 이런 규제를 L2규제라고도 한다.
이진분류에서는 시그모이드 함수를 이용해 Z를 0과 1 사이값으로 변환한다. 이와 달리, 다중 분류는 소프트맥스 함수로 Z값을 확률로 변환한다.

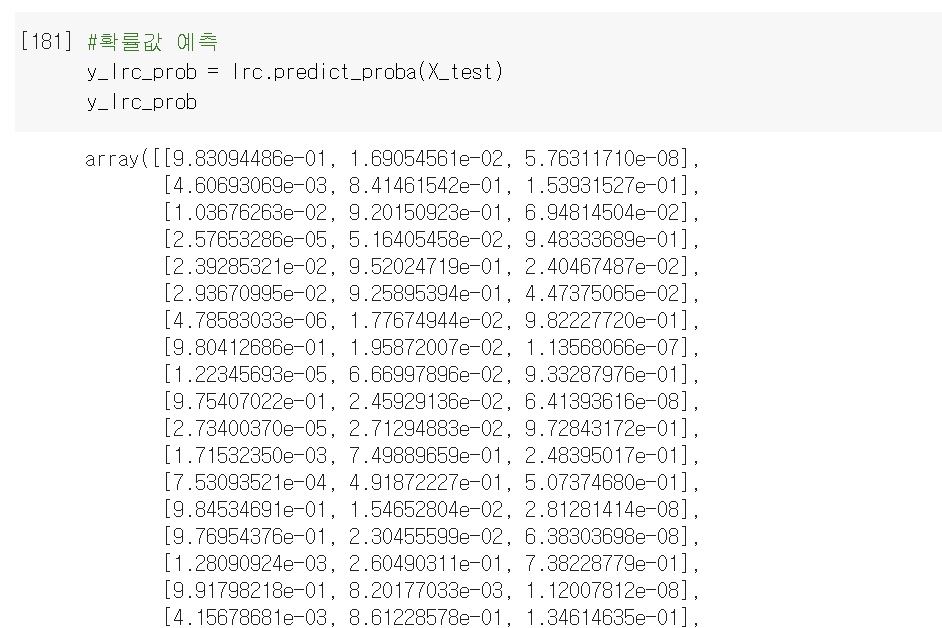
첫 번째 열은 클래스 0의 예측 확률, 두번째 열은 클래스 1의 예측 확률, 세번째 열은 클래스 2의 예측 확률이다.
첫 번째 행의 값을 보면 0번째 열의 예측 확률이 0.98로 가장 크기 때문에 첫번째 샘플은 클래스 0으로 분류된다.
의사결정나무 모델은 트리 알고리즘을 사용한다. 트리의 각 분기점에는 데이터셋의 피처를 하나씩 위치시킨다.
각 분기점에서 해당 피처에 관한 임의의 조건식을 가지고 계속 2개 이상의 줄기로 가지를 나누면서 데이터를 구분한다.
과대적합되는 것을 방지하기 위해 트리의 최대 깊이는 3으로 설정한다. 약 93.33%의 정확도를 갖는다.

728x90
'AI > Machine Learning&Deep Learning' 카테고리의 다른 글
| MachineLearning_교차 검증 (0) | 2021.03.22 |
|---|---|
| MachineLearning_앙상블 모델 (0) | 2021.03.22 |
| MachineLearning_SVM 분류 알고리즘 (0) | 2021.03.22 |
| MachineLearning_KNN 분류 알고리즘 (0) | 2021.03.22 |
| MachineLearning_분류(Classification) (0) | 2021.03.22 |