



판다스 데이터프레임에 corr 메소드를 적용하면 숫자 데이터를 갖는 변수 간의 상관 계수를 계산한다.
시본의 heatmap 함수를 사용하면 상관 계수 테이블을 시각화 할 수 있다. 목표 변수인 Target 열은
RM 변수와 상관 계수가 0.69이고, LSTAT 변수와 -0.73으로 높은 편이다.

행 기준으로는 Target을 제외한 나머지 변수를 모두 선택하고, 열 기준으로는 Target을 선택한다.
abs는 상관계수 값을 모두 양의 값으로 바꾼다.

LSTAT와 RM의 선형 관계가 뚜렷하다.



LSTAT와 RM은 목표 변수인 Target과 강한 선형 관계를 갖기 때문에 이 둘을 학습데이터(X_data)로 선택한다.

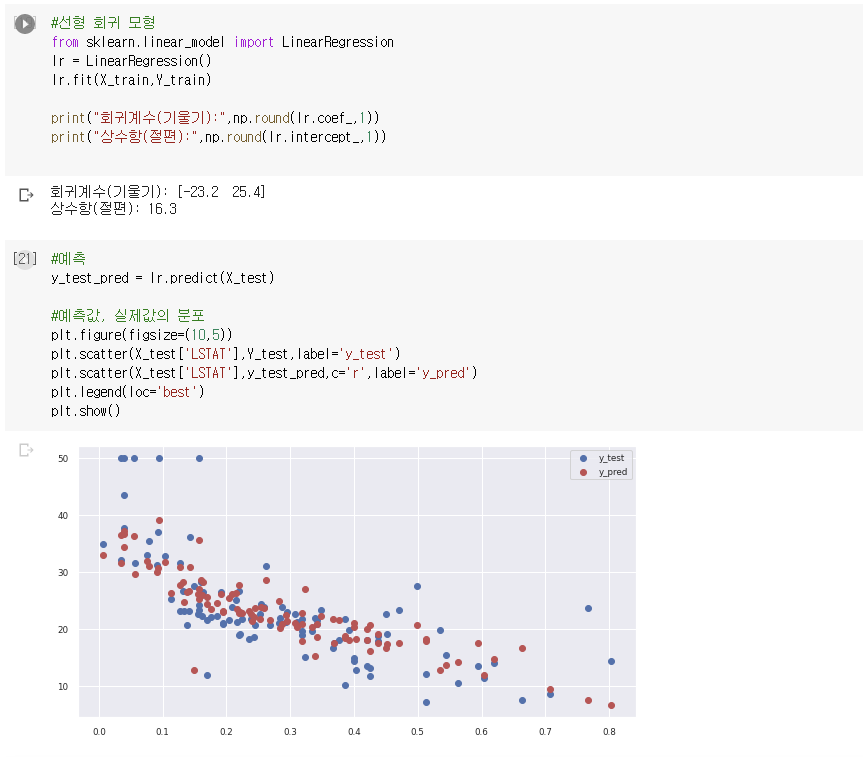
선형회귀 모델의 coef_ 속성으로부터 각 피처에 대한 회귀계수 값을 얻고 intercept_ 속성에서 상수항을 얻는다.
LSTAT 회귀계수는 -23.2고, RM은 25.4DLEK. 따라서 저소득층 비율이 클수록 주택 가격(TARGET) 값은 작아지는
반면, 방의 개수가 클수록 주택 가격은 커진다.

과대적합은 모델이 학습에 사용한 데이터와 비슷한 데이터는 잘 예측하지만, 경험해 보지 못한 새로운 특성을 갖는 데이터에 대해서는 예측력이 떨어지는 현상을 말한다. 반대로 과소적합은 훈련 데이터의 특성을 파악하기 충분하지 않을 정도로 모델의 구성이 단순하거나 데이터 개수가 부족할 때 발생한다. 모델의 예측력을 안정적으로 확보하기위해서는 과대적합이나 과소적합이 아닌 중간 상태의 균형점을 찾는 것이 필요하다.
'AI > Machine Learning&Deep Learning' 카테고리의 다른 글
| Machine Learning_선형 회귀 (0) | 2021.03.27 |
|---|---|
| Machine Learning_K-최근접 이웃 회귀 (0) | 2021.03.27 |
| MachineLearning_교차 검증 (0) | 2021.03.22 |
| MachineLearning_앙상블 모델 (0) | 2021.03.22 |
| MachineLearning_로지스틱 회귀&의사결정나무 (0) | 2021.03.22 |